So kannst du mit dem StringTokenizer Java Strings splitten und teilen

Java StringTokenizer – was ist das?
Bevor ich diese Frage kläre, schiebe ich eine zweite Frage hinterher.
Denn im Wort Tokenizer steckt das Wort Token.
Also was ist ein Token?
Hier die Definition zum Token:
Ein Token ist eine bestimmte Aneinanderreihung von Zeichen.
Man kann auch sagen, eine lexikalische Einheit.
Das kann zum Beispiel eine Zahl, wie 1782 oder ein Wort oder ein einzelner Buchstabe sein.
Der Java Compiler erkennt diese Zeichenfolge, da er die Wörter und die Grammatik von Java kennt.
Getrennt werden Token durch Leerzeichen bzw. durch das Ende der Zeichenketten.
Klingt kompliziert?
Ist es aber eigentlich nicht.
Wir werden in diesem Beitrag einen String, nach einzelne Token oder nach einzelnen Wörter zerlegen bzw. aufteilen.
Und das ganze machen wir mit einem Objekt der Klasse String Tokenizer.
Inhalt
Werfen wir einen Blick in die Java Klasse – String Tokenizer.
In den Java API Docs wird auch diese Klasse dokumentiert.
Ganz oben siehst du die Importanweisung, um ein Objekt der Klasse zu erstellen.
Wenn du etwas weiter nach unten scrollst, siehst du die Konstruktoren und Methoden.
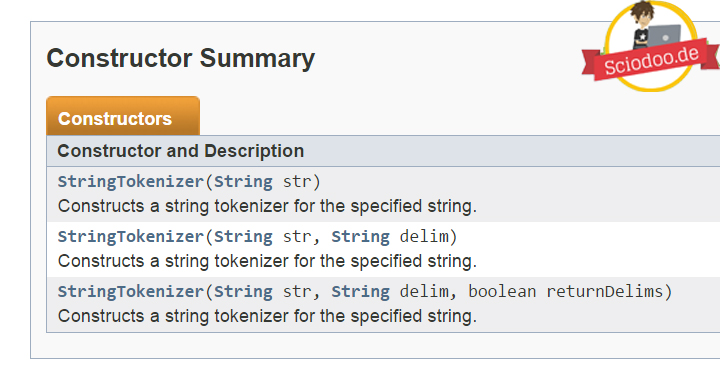
Beginnen wir bei den Konstruktoren.
Die Klasse StringTokenizer bietet dir drei verschiedene Konstruktoren an.
Der erste Konstruktor erwartet lediglich einen String.
So wie hier in diesem Beispiel:
import java.util.StringTokenizer;//Importanweisung
public class StringTokenizerDemo {
public static void main(String[] args) {
StringTokenizer strToken = new StringTokenizer("Das ist ein Beispiel");// StringTokenizer Objekt
}
}
Natürlich kannst du dem Tokenizer auch eine Refernzvariable übergeben, welche auf ein String-Objekt zeigt.
So wie hier.
import java.util.StringTokenizer;//Importanweisung
public class StringTokenizerDemo {
public static void main(String[] args) {
String textFuerTokenizer="Das ist ein Beispiel";
StringTokenizer strToken = new StringTokenizer(textFuerTokenizer);
}
}
Wenn du einen sehr großen Text mit Umbrüchen übergeben möchtest, kannst du die Variablendeklaration und -initialisierung auch in zwei Schritten vollziehen.
Dadurch wird es etwas übersichtlicher. So wie hier:
import java.util.StringTokenizer;//Importanweisung
public class StringTokenizerDemo {
public static void main(String[] args) {
String textFuerTokenizer;
textFuerTokenizer= "Das ist mein Beispieltext für den StringTokenizer."
+ "Dieser Text soll zerlegt werden."
+ "Und zwar Token für Token."
+ "Eine Schleife soll dann die einzelnen Token auf der Konsole anzeigen";
StringTokenizer strToken = new StringTokenizer(textFuerTokenizer);
}
}
So nun hat der Konstruktor ein String übergeben bekommen.
Also was machst du jetzt damit?
Die Klasse StringTokenizer bietet eine Methode, namens nextToken() an.
Und diese Methode kannst du am Objekt aufrufen.

Die Methode returnt dir einen String, welchen du in einer neuen Referenzvariable speichern musst.
Und diesen neuen Textwert kannst du dir dann auf der Konsole anzeigen lassen.
import java.util.StringTokenizer;
public class StringTokenizerDemo {
public static void main(String[] args) {
String textFuerTokenizer;
textFuerTokenizer= "Das ist mein Beispieltext für den StringTokenizer."
+ "Dieser Text soll zerlegt werden."
+ "Und zwar Token für Token."
+ "Eine Schleife soll dann die einzelnen Token auf der Konsole anzeigen";
StringTokenizer strToken = new StringTokenizer(textFuerTokenizer);
String textRueckgabe = strToken.nextToken();//Rückgabewert wird gespeichert
System.out.println(textRueckgabe);//gespeicherter Wert wird auf der Konsole ausgegeben
}
}
Wenn du so wie ich, nur die Bildschirmausgabe benötigst – kannst du die Methodenrückgabe auch gleich in eine system.out.println()-Anweisung einbetten.
import java.util.StringTokenizer;
public class StringTokenizerDemo {
public static void main(String[] args) {
String textFuerTokenizer;
textFuerTokenizer= "Das ist mein Beispieltext für den StringTokenizer."
+ "Dieser Text soll zerlegt werden."
+ "Und zwar Token für Token."
+ "Eine Schleife soll dann die einzelnen Token auf der Konsole anzeigen";
StringTokenizer strToken = new StringTokenizer(textFuerTokenizer);
System.out.println(strToken.nextToken());//Rückgabe - Das
System.out.println(strToken.nextToken());//Rückgabe - ist
System.out.println(strToken.nextToken());//Rückgabe - mein
}
}
Wie auch immer.
Klicke auf „RUN“ und die ersten drei Token erscheinen auf der Konsole.
Okay-schauen wir uns den nächsten Konstruktor der StringTokenizer Klasse an.
Der zweite Konstruktor der Klasse String Tokenizer erwartet noch einen String.
Jetzt kannst du im zweiten String festlegen, welche Trennzeichen beachtet werden sollen.
Der erste Konstruktor trennt nach Leerzeichen.
Und diesen Konstruktor kannst du zum Beispiel nach Satzpunkten trennen lassen.
import java.util.StringTokenizer;
public class StringTokenizerDemo {
public static void main(String[] args) {
String textFuerTokenizer;
textFuerTokenizer= "Das ist mein Beispieltext für den StringTokenizer."
+ "Dieser Text soll zerlegt werden."
+ "Und zwar Token für Token."
+ "Eine Schleife soll dann die einzelnen Token auf der Konsole anzeigen";
StringTokenizer strToken = new StringTokenizer(textFuerTokenizer,".");//Jetzt wird nur noch am Punkt getrennt
System.out.println(strToken.nextToken());//Rückgabe - Das ist mein Beispieltext für den StringTokenizer
System.out.println(strToken.nextToken());//Rückgabe - Dieser Text soll zerlegt werden
System.out.println(strToken.nextToken());//Rückgabe - Und zwar Token für Token
}
}
Klicke wieder auf „RUN“ und jetzt sollte der erste Satz auf der Konsole ausgegeben werden.
Aber du kannst diesem Konstruktor noch viel mehr Trennungsregeln mitgeben.
Füge doch zum Satzpunkt noch ein „z“ ein.
import java.util.StringTokenizer;
public class StringTokenizerDemo {
public static void main(String[] args) {
String textFuerTokenizer;
textFuerTokenizer= "Das ist mein Beispieltext für den StringTokenizer."
+ "Dieser Text soll zerlegt werden."
+ "Und zwar Token für Token."
+ "Eine Schleife soll dann die einzelnen Token auf der Konsole anzeigen";
StringTokenizer strToken = new StringTokenizer(textFuerTokenizer,".z");//Jetzt wird am Punkt und am z getrennt
System.out.println(strToken.nextToken());//Rückgabe - Das ist mein Beispieltext für den StringTokeni
System.out.println(strToken.nextToken());//Rückgabe - er
System.out.println(strToken.nextToken());//Rückgabe - Dieser Text soll
}
}
Jetzt trennt der Tokenizer den ersten Satz schon beim ersten Auftreten des Buchstaben „z“.
Wenn du die Methode nextToken() nochmals aufrufst, zerlegt der Tokenizer den übrigen Text weiter.
Und zwar so weit, bis das nächste „z“ oder der nächste Satzpunkt erscheint.
Klicke wieder auf „RUN“ und schau dir die Ausgabe an.
Blöd ist nur, dass der Tokenizer die Trennungszeichen verschluckt.
- Denn der erste Token lautet: Das ist mein Beispieltext für den StringTokeni
- Und der zweite lautet: er
- Der dritte lautet dann: Dieser Text soll
Du siehst – der Satzpunkt und das „z“ wurden verschluckt.
Und um dies zu regeln, benötigst du den dritten Konstruktor.
Beim dritten Konstruktoraufruf kannst du dem Tokenizer sagen, ob die Trennungszeichen mit ausgegeben werden sollen.
Beim Aufruf des dritten Konstruktors, übergibst du einen weiteren Parameter.
Dieser ist ein boolean.
Du übergibst entweder true oder false, als Argument.
Im Falle von true werden dann die Trennzeichen auf der Konsole mit ausgegeben.
So wie hier:
import java.util.StringTokenizer;
public class StringTokenizerDemo {
public static void main(String[] args) {
String textFuerTokenizer;
textFuerTokenizer= "Das ist mein Beispieltext für den StringTokenizer."
+ "Dieser Text soll zerlegt werden."
+ "Und zwar Token für Token."
+ "Eine Schleife soll dann die einzelnen Token auf der Konsole anzeigen";
StringTokenizer strToken = new StringTokenizer(textFuerTokenizer,".z",true);//mit Trennungszeichen
System.out.println(strToken.nextToken());//Rückgabe - Das ist mein Beispieltext für den StringTokeni
System.out.println(strToken.nextToken());//Rückgabe - z
System.out.println(strToken.nextToken());//Rückgabe - er
}
}
Und im Falle von false, werden die Trennungszeichen verschluckt.
So wie hier:
import java.util.StringTokenizer;
public class StringTokenizerDemo {
public static void main(String[] args) {
String textFuerTokenizer;
textFuerTokenizer= "Das ist mein Beispieltext für den StringTokenizer."
+ "Dieser Text soll zerlegt werden."
+ "Und zwar Token für Token."
+ "Eine Schleife soll dann die einzelnen Token auf der Konsole anzeigen";
StringTokenizer strToken = new StringTokenizer(textFuerTokenizer,".z",false);//ohne Trennugszeichen
System.out.println(strToken.nextToken());//Rückgabe - Das ist mein Beispieltext für den StringTokeni
System.out.println(strToken.nextToken());//Rückgabe - er
System.out.println(strToken.nextToken());//Rückgabe - Dieser Text soll
}
}
Die Methoden des Java StringTokenizer.
Eine Methode hast du bereits benutzt.
Die Methode nextToken() gibt beim Aufruf immer den nächsten Token zurück.
Sie returnt einen String. Und deshalb musst du den Rückgabewert entweder speichern oder in eine Konsolenausgabe implementieren.
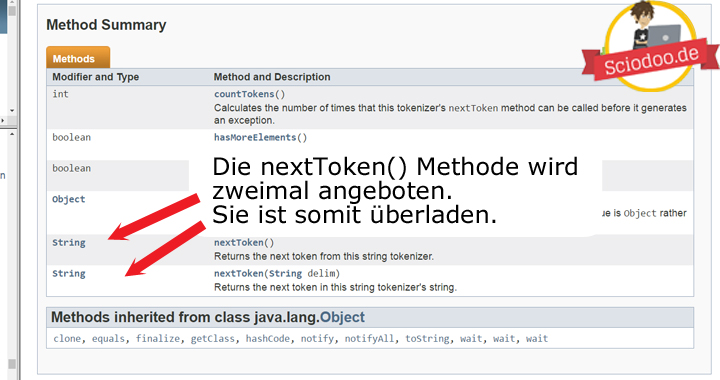
Die Methode nextToken() ist überladen.
Denn du kannst ihr beim Aufruf auch ein Trennzeichen als String übergeben.
Und dann werden die Token, in Abhängigkeit vom Trennzeichen zurück gegeben.
import java.util.StringTokenizer;
public class StringTokenizerDemo {
public static void main(String[] args) {
String textFuerTokenizer;
textFuerTokenizer= "Das ist mein Beispieltext für den StringTokenizer."
+ "Dieser Text soll zerlegt werden."
+ "Und zwar Token für Token."
+ "Eine Schleife soll dann die einzelnen Token auf der Konsole anzeigen";
StringTokenizer strToken = new StringTokenizer(textFuerTokenizer);
System.out.println(strToken.nextToken("ü"));//Rückgabe - Das ist mein Beispieltext f
System.out.println(strToken.nextToken("."));//Rückgabe - ür den StringTokenizer
System.out.println(strToken.nextToken("s"));//Rückgabe - .Die
}
}
Eine weitere Methode ist countToken().
Diese Methode gibt beim Aufruf die mögliche Anzahl der nextToken()-Aufrufe zurück.
Sie returnt einen Integer-Wert, welchen du entweder speichern oder in eine Konsolenausgabe packen kannst.
import java.util.StringTokenizer;
public class StringTokenizerDemo {
public static void main(String[] args) {
String textFuerTokenizer;
textFuerTokenizer= "Das ist mein Beispieltext für den StringTokenizer."
+ "Dieser Text soll zerlegt werden."
+ "Und zwar Token für Token."
+ "Eine Schleife soll dann die einzelnen Token auf der Konsole anzeigen";
StringTokenizer strToken = new StringTokenizer(textFuerTokenizer);
System.out.println(strToken.countTokens());//Rückgabe - 25 -die Anzahl der möglichen Aufrufe
}
}
Die Methode countToken() kann dir aber auch die Anzahl der Sätze liefern.
So wie hier:
import java.util.StringTokenizer;
public class StringTokenizerDemo {
public static void main(String[] args) {
String textFuerTokenizer;
textFuerTokenizer= "Das ist mein Beispieltext für den StringTokenizer."
+ "Dieser Text soll zerlegt werden."
+ "Und zwar Token für Token."
+ "Eine Schleife soll dann die einzelnen Token auf der Konsole anzeigen";
StringTokenizer strToken = new StringTokenizer(textFuerTokenizer,".");//Trennungsregel Satzpunkt
System.out.println(strToken.countTokens());//Rückgabe - 4 -die Anzahl der Sätze
}
}
Eine weitere Methode ist die Methode hasMoreToken().

Die Methode hasMoreToken() returnt einen boolean.
Also entweder wahr oder falsch. Beziehungsweise true oder false.
Sie prüft, ob der Text noch weitere Token enthält.
Bei weiteren Token gibt sie den Wert true aus.
Ansonsten returnt sie den Wert false.
Hier das Beispiel dazu:
import java.util.StringTokenizer;
public class StringTokenizerDemo {
public static void main(String[] args) {
String textFuerTokenizer;
textFuerTokenizer= "Das ist mein Beispieltext für den StringTokenizer."
+ "Dieser Text soll zerlegt werden."
+ "Und zwar Token für Token."
+ "Eine Schleife soll dann die einzelnen Token auf der Konsole anzeigen";
StringTokenizer strToken = new StringTokenizer(textFuerTokenizer,".");//Trennungsregel Satzpunkt
System.out.println(strToken.nextToken());//Rückgabe - Das ist mein Beispieltext für den StringTokenizer
System.out.println(strToken.hasMoreTokens());//Gibt es weitere Token? - Rückgabe= true
System.out.println(strToken.nextToken());//Rückgabe - Dieser Text soll zerlegt werden
System.out.println(strToken.hasMoreTokens());//Gibt es weitere Token? - Rückgabe = true
System.out.println(strToken.nextToken());//Rückgabe - Und zwar Token für Token
System.out.println(strToken.hasMoreTokens());//Gibt es weitere Token? - Rückgabe=true
System.out.println(strToken.nextToken());//Rückgabe - Eine Schleife soll dann die einzelnen Token auf der Konsole anzeigen
System.out.println(strToken.hasMoreTokens());//Gibt es weitere Token? - Rückgabe = false
}
}
So kannst du einen Java String mit dem StringTokenizer und einer Schleife zerlegen bzw. aufsplitten.
Jetzt brauchst du sämtliche Methoden.
Und zwar soll eine Schleife den Text Stück für Stück zurückgeben.
Welcher Schleifentyp ist dafür am besten geeignet?
Die Anzahl der Token ist erst einmal unbekannt.
Und somit ist die Anzahl der Schleifendurchläufe ebenfalls unbekannt.
Es ist deshalb sinnvoll, eine while Schleife einzusetzen.
So kannst du einen String mit dem StringTokenizer und einer while Schleife zerlegen.
Schau dir die Methoden des String Tokenizer nochmals an.
Diese Klasse gibt dir die Methode hasMoreToken() an die Hand.
Die Methode prüft, ob weitere Token existieren.
Es bietet sich also an, diese Methodenrückgabe als Schleifenbedingung einzusetzen.
hasMoreToken() == true
Und hier der Java Code zu diesem Beispiel.
import java.util.StringTokenizer;
public class StringTokenizerDemo {
public static void main(String[] args) {
String textFuerTokenizer;
textFuerTokenizer= "Das ist mein Beispieltext für den StringTokenizer."
+ "Dieser Text soll zerlegt werden."
+ "Und zwar Token für Token."
+ "Eine Schleife soll dann die einzelnen Token auf der Konsole anzeigen";
StringTokenizer strToken = new StringTokenizer(textFuerTokenizer," .");//Trennungsregel Leerzeichen und Punkt
while (strToken.hasMoreTokens()==true){
System.out.println(strToken.nextToken());//Ausgabe Token für Token bzw. Wort für Wort
}
}
}
Als Trennungsregel habe ich den Satzpunkt und das Leerzeichen verwendet.
Somit wurde dieser Java String Wort für Wort zerlegt.
Analog dazu kannst du aber auch nur den Punkt, als Trennungszeichen verwenden.
Dann wird die Schleife den String – Satz für Satz zerlegen.
Zusammenfassung:
- Java Strings lassen sich mit dem Java StringTokenizer teilen.
- Die Java Klasse String Tokenizer bietet dir dafür drei verschiedene Konstruktoren und ein paar Methoden an.
- In Zusammensetzung mit einer while Schleife kannst du einen String in seine Einzelteile zerlegen.
Über den Autor
